
En el sector industrial, la detección temprana de anomalías en maquinaria y equipos es clave para optimizar el mantenimiento y evitar fallos catastróficos. Con el auge del mantenimiento predictivo basado en datos, las técnicas de machine learning han demostrado ser herramientas poderosas para identificar patrones irregulares en el funcionamiento de los sistemas. Entre estas técnicas, el clustering se ha convertido en una metodología fundamental para la detección de anomalías en bases de datos industriales, como el conjunto de datos TLMUAV Anomaly Detection
Importancia del Clustering en la Detección de Anomalías
El clustering es una técnica de aprendizaje no supervisado que agrupa datos similares sin necesidad de etiquetas predefinidas. En el contexto del mantenimiento predictivo, permite descubrir patrones ocultos en grandes volúmenes de datos, ayudando a identificar condiciones anómalas que podrían indicar fallos incipientes.
Algunas de las ventajas del clustering en la detección de anomalías incluyen:
- Identificación de patrones anormales en datos operacionales.
- Reducción del tiempo de detección de fallas.
- Análisis exploratorio sin necesidad de datos etiquetados.
Implementación Práctica
La aplicación de estas técnicas en el dataset TLMUAV Anomaly Detection Datasets permite clasificar el estado de los equipos y detectar eventos anormales en su funcionamiento. Una estrategia efectiva consiste en:
- Preprocesar los datos: Normalización y eliminación de valores atípicos extremos.
- Aplicar clustering: Utilizar K-Means o DBSCAN para agrupar los datos y detectar posibles outliers.
- Validar los resultados: Comparar las anomalías detectadas con eventos reales de fallo para evaluar la precisión del modelo.
Técnicas de Clustering Utilizadas
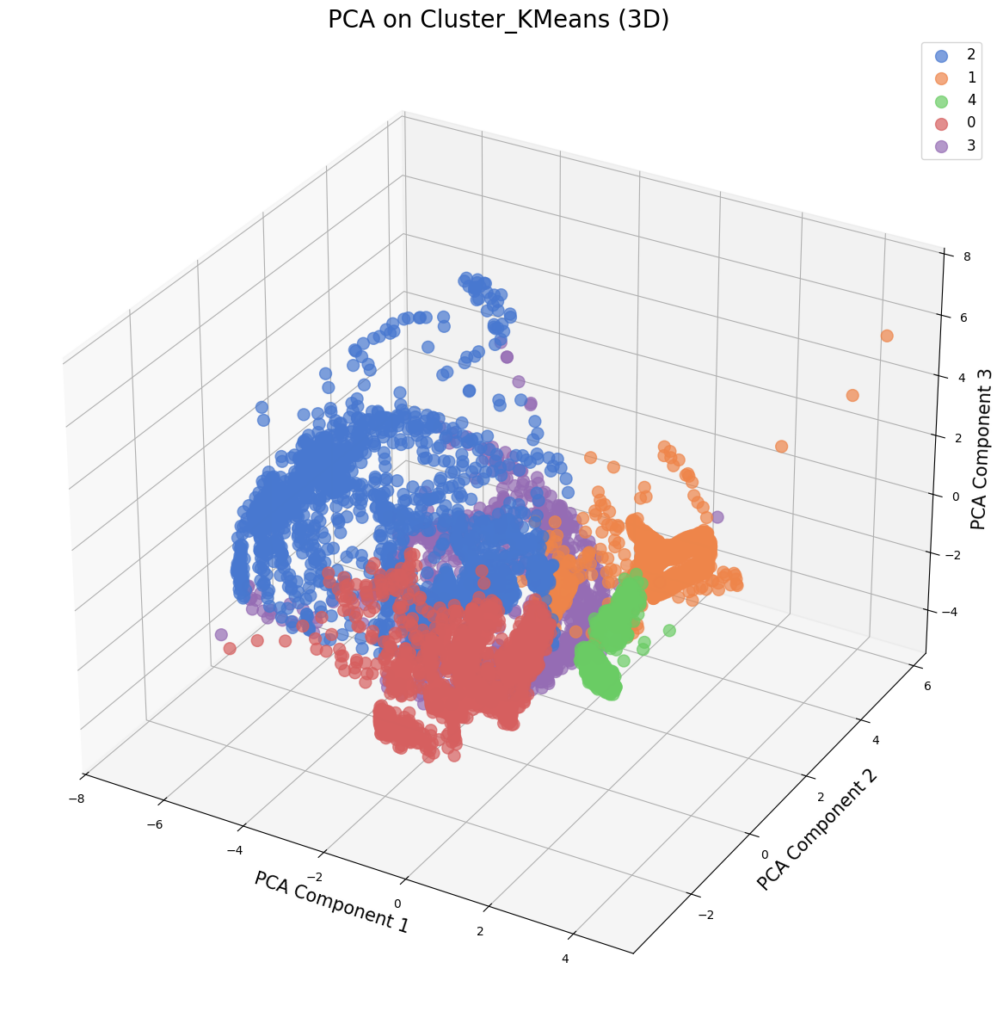
1. K-Means Clustering
Una de las técnicas más utilizadas en detección de anomalías. Funciona dividiendo los datos en K grupos y asignando cada punto de datos al clúster con la media más cercana. Las observaciones que quedan aisladas o tienen una distancia significativamente mayor al centroide pueden considerarse anómalas.
2. Gaussian Mixture Model (GMM)
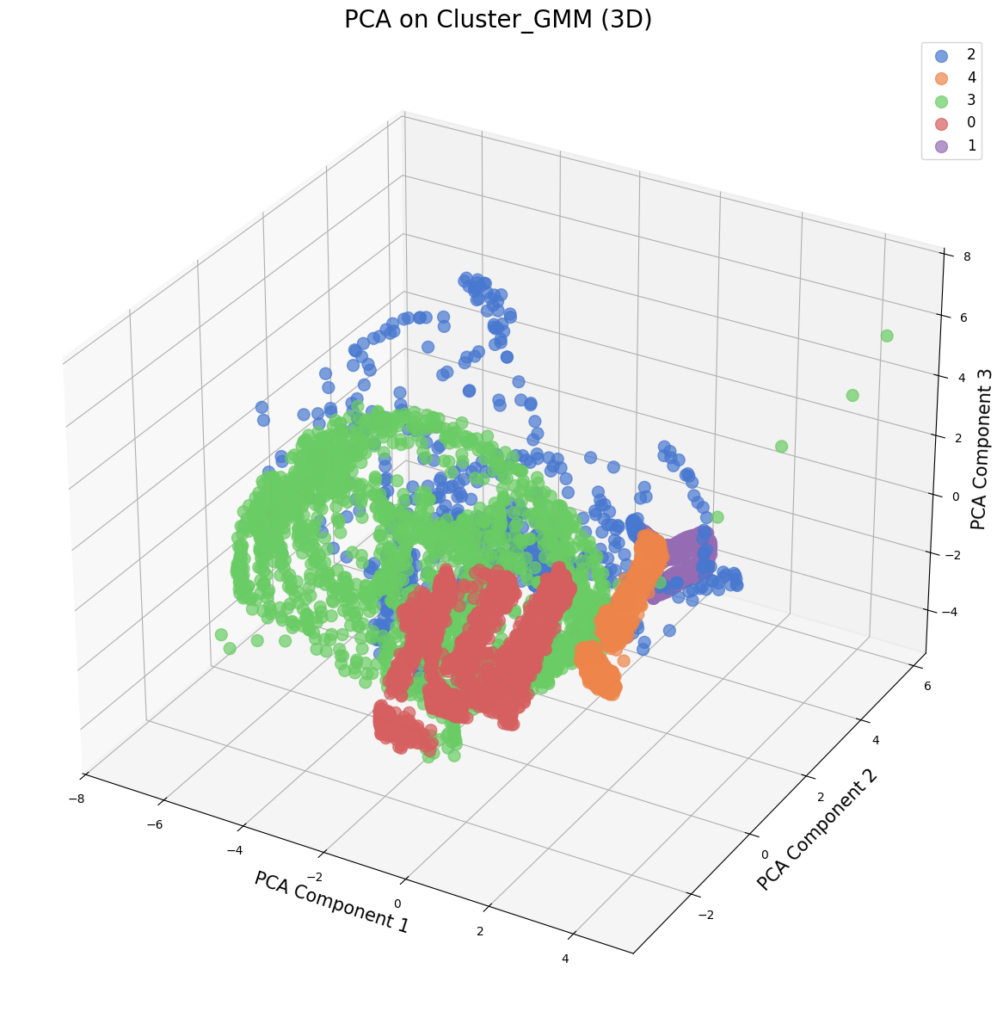
GMM es un modelo basado en la teoría de distribuciones gaussianas que asume que los datos provienen de múltiples distribuciones normales superpuestas. A diferencia de K-Means, que asigna puntos a un solo clúster, GMM estima la probabilidad de pertenencia de cada punto a distintos clústeres. En la detección de anomalías, los puntos con probabilidades bajas en todas las distribuciones pueden ser identificados como atípicos.
3. Aglomerative Clustering
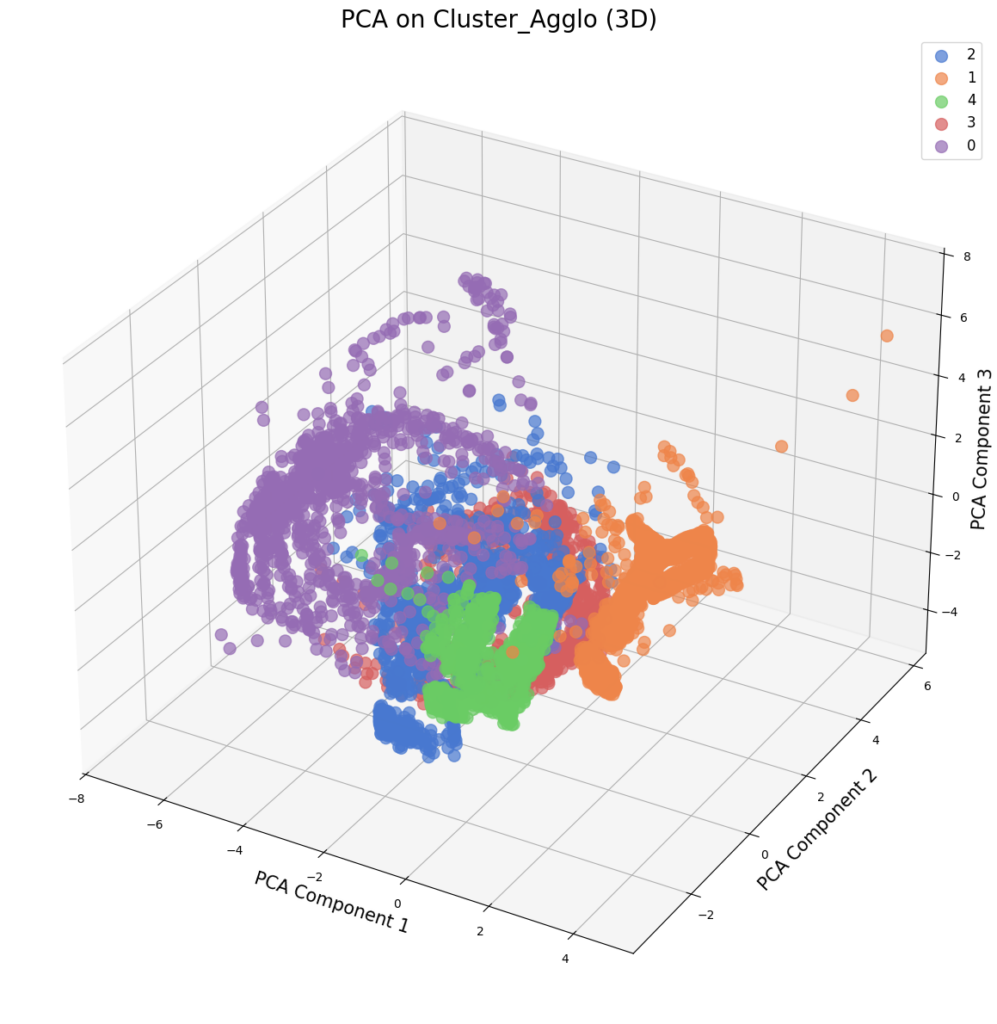
Este método jerárquico agrupa los datos en una estructura de árbol, fusionando iterativamente los puntos más similares hasta formar un solo clúster. En la detección de anomalías, se pueden analizar las distancias entre los datos y sus respectivos grupos, identificando aquellos que se encuentran significativamente alejados de su clúster asignado como posibles anomalías.
Conclusión
El clustering en la detección de anomalías para el mantenimiento predictivo es una estrategia eficaz para anticipar fallos y optimizar el rendimiento de los equipos industriales. La integración de técnicas como K-Means, Aglomerative Clustering y GMM permite identificar y clasificar anomalías en entornos sin etiquetas de fallos, mejorando la capacidad de diagnóstico y la toma de decisiones en el mantenimiento.