
La elección del «mejor» modelo predictivo para un caso de uso práctico de Mantenimiento Predictivo debe realizarse de manera razonada y no en función de mejores o peores resultados con datos de entrenamiento y/o test, o en base a la tendencia generalizada del uso de modelos «de moda» como los modelos «deep learning» de uso generalizado.
Aspectos adicionales como el tiempo en la obtención de los modelos (lo que de manera común suelen llamar algunos «el aprendizaje») o bien aspectos normativos (véase la AI Act aprobada recientemente), deben ser tenidos en cuenta.
Ilustremos esto con un caso práctico recientemente terminado, en el que se prueban distintos algoritmos de clasificación con el objeto de «predecir» el fallo de un sistema a partir de un conjunto de características (variables) básicas.
Obtenidos los modelos convenientemente tras efectuar ls operaciones pertinentes relativas a los dominios de procesamiento de Datos, e Ingeniería de Características, obtenemos unos valores para los mismos como los siguientes:
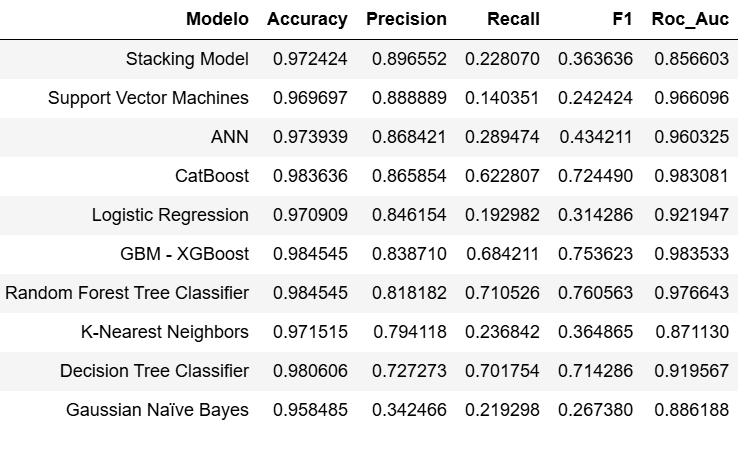
Podríamos decir que todos ellos tienen «un buen comportamiento». Es lógico debido a la «sencillez» del problema planteado que se refleja en los datos y variables utilizados.
Veamos cuanto tiempo ha empleado una máquina del alto rendimiento en obtener los modelos:
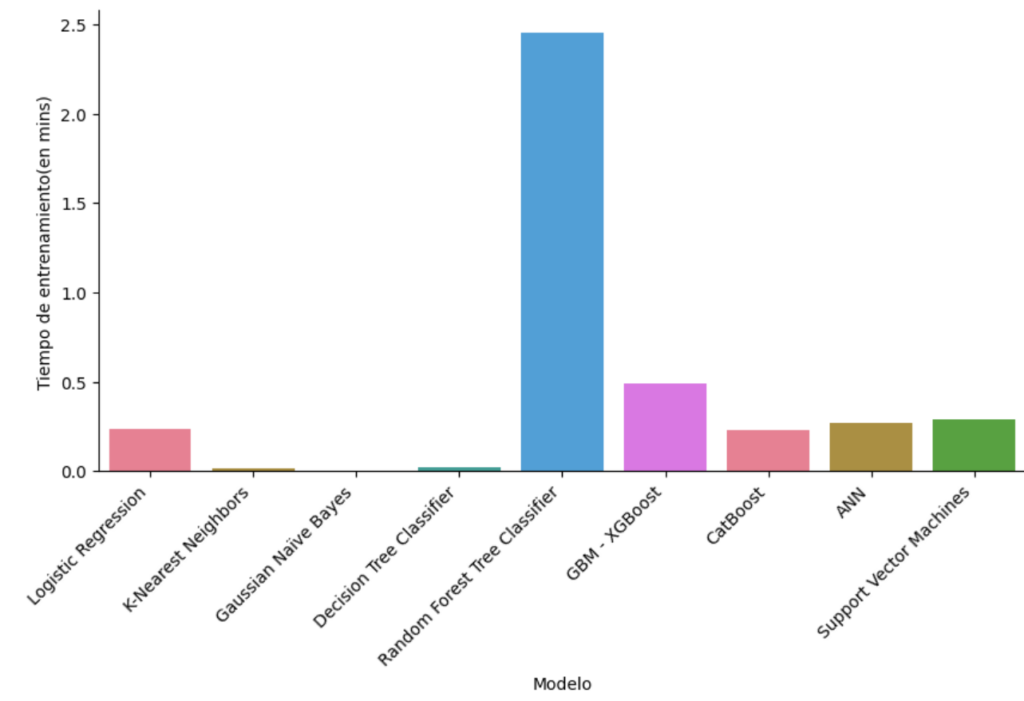
Observamos que hay modelos que utilizan tiempos muy superiores a otros.
En este sentido, a la hora de llevar el «mejor» modelo a producción en una empresa, teniendo en cuenta que los datos se obtienen en tiempo real a partir de dispositivos IoT, de forma que los modelos se deben estar obteniendo de forma recurrente (re-entrenamiento dinámico), y que el sistema en cuestión es sensible a variaciones mínimas de precisión, dado que pudiera ser un radar que direcciona un proyectil, ¿qué modelo elegimos? ….
Ah, se me olvidaba la nueva Ley de IA … ¿podemos usar cualquiera de esos modelos?
Como se suele decir «ahí lo dejo ….»