
Los procedimientos con los que tratamos los datos han cambiado de maneras increíbles en los últimos años. Hoy en día escuchamos la palabra Big Data a nuestro alrededor, estos son datos que se recogen de una manera muy rápida, que son grandes volúmenes de datos y que además vienen en diferentes tipos de formatos (texto, audio, imágenes…)
Por eso la generación de datos sintéticos puede parecer innecesario ¿Por qué generaría más datos si simplemente puedo recoger más, si con el Big Data tengo datos de sobra?
Antes de responder, y como buen matemático que soy, quiero empezar por definir qué es un dato sintético. En el reporte sobre datos sintéticos del “The Alan Turing institude “[1], definen los datos sintéticos como:
“Datos que han sido generados usando un modelo matemático o algoritmos, y que tienen el objetivo de resolver problemas del ámbito de la ciencia de datos.”
La primera parte de esta definición nos diferencia entre los dos tipos de generación de datos:
- Modelos “Physics Based” o “Basados en Física”: Estos son los modelos matemáticos que se nombran en la definición, se basan en crear modelos que simulan cómo funciona la física de los componentes de un objeto y como interaccionan entre ellos y con el medio. Así por ejemplo podríamos utilizar modelos matemáticos para simular la física de un coche, y utilizar ese coche simulado para generar datos (podéis ver el artículo de mi compañero Jesús si os ha sonado interesante)
- Modelos “Data Driven” o “Basados en datos”: Estos son los modelos originados de algoritmos, que utilizan los datos ya existentes de objetos, y utilizan herramientas de ciencias de datos como estadística o Aprendizaje Automático para generar nuevos modelos a partir de los existentes. En este caso, y por continuar con el ejemplo del coche, tendríamos datos de cientos o miles de coches diferentes y a raíz de eso nuestros algoritmos aprenderían cómo funciona un coche y serían capaces de generar datos a partir de ese conocimiento.
La segunda parte de la definición responde a la pregunta que introducíamos antes: ¿Por qué generar más datos? La respuesta es que los necesitamos para resolver un problema en específico, algunos ejemplos serían:
- Problemas en los que los datos de interés son escasos: En los que tenemos muchos datos de lo que ocurre “normalmente” pero no de la excepción. Por ejemplo: Casos de enfermedades raras, casos de fraude en bancos, o accidentes aéreos.
- Problemas en los que generar el dato físico cuesta muchos recursos: Ya sea este recurso tiempo, dinero, salud, … Por ejemplo: No infectaríamos a una persona real para tener más datos de una enfermedad al igual que no estrellaríamos un avión solo para tener datos de la situación.
- Los datos de interés no han sido recogidos: Puede ser que el suceso haya ocurrido y no se hayan monitorizado los datos, o que los sensores no sean capaces de recoger los datos que nos interesan. Por ejemplo: una persona enferma que ha estado en casa y no se han tomado sus valores hasta llegar al hospital, cuando los valores de antes pudiesen haber servido para prevenir el problema
Una vez entendidas la definición y la necesidad de estas técnicas en algunos casos, profundizamos en los modelos Basados en datos. Aquí presentaremos dos modelos que estamos estudiando, de diferente complejidad y que pueden ser usados para crear datos sintéticos basados en los datos ya existentes:
SMOTE
La técnica Synthetic Minority Over-sampling Technique (SMOTE) fue introducida en 2002 [2], como una técnica para generar datos sintéticos de la clase minoritaria en problemas de caracterización, el incentivo de este problema es que un punto generado cerca del centroide de dos o mas puntos será similar a todos los puntos que lo han creado.
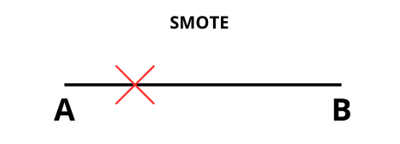
La técnica es sencilla, si queremos generar un punto entre los puntos A y B, hacemos una línea entre ellos y generamos un número (normalmente denominado Alpha) que tiene valores entre 0 y 1. De tal manera que un valor más cercano de Alpha a 0 nos daría un punto más cercano a A, y un valor mas cercano a 1 nos daría un punto más cercano a B.
Esta técnica también se puede utilizar cuando queremos generar un punto usando más de dos puntos:
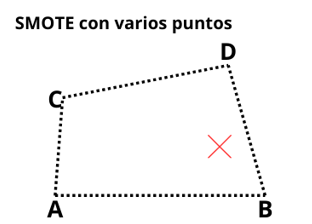
En este caso (con 4 puntos) tendríamos un cuadrilátero, y el punto generado quedaría en algún lugar dentro de este. Aquí se introducen varios valores Alpha, al igual que hay que asegurar que la suma de estos de 1, pero la idea es la misma que con dos puntos, solo que generalizada.
GAN
Las Generative Adversarial Nets (GAN) fueron introducidas en 2014 por un equipo de la universidad de Montreal en 2014 [3]. Aunque son una estructura compleja de Lenguaje Profundo, la idea que hay detrás de ellas es simple, una estructura GAN esta formada por dos arquitecturas de Redes Neuronales:
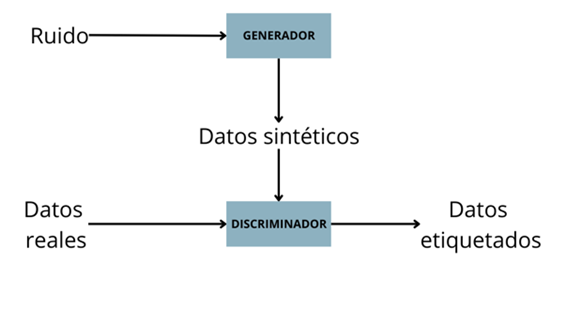
- Generador: Toma de entrada ruido y lo usa para generar datos sintéticos con la estructura de los datos reales. Su objetivo es crear datos sintéticos que se parezcan a los reales
- Discriminador: Toma de entrada datos reales y datos sintéticos La salida de esta red neuronal serán los datos etiquetados como “reales” o “sintéticos”. Su objetivo es intenta averiguar cuáles son los datos reales y cuales los sintéticos.
La intuición de esta red es que si entrenamos y conseguimos un buen generador y discriminador conseguiremos crear datos sintéticos buenos y que además son capaces de confundir a un buen discriminador.
Nos hemos centrado en estos ejemplos ya que son los que estamos estudiando para introducir en el proyecto, si te ha interesado la creación de datos sintéticos, estate atento a la web.
Referencias
[1] Jordon, J., Szpruch, L., Houssiau, F., Bottarelli, M., Cherubin, G., Maple, C., … & Weller, A. (2022). Synthetic Data–what, why and how?. arXiv preprint arXiv:2205.03257.
[2] Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, 321-357.
[3] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. Advances in neural information processing systems, 27.