
La detección de anomalías es el arte de encontrar lo raro. En un conjunto de datos, una anomalía es algo que se comporta de forma diferente al resto. Puede ser una transacción fraudulenta, una lectura inusual de un sensor, o un movimiento extraño de un dron.
El problema: en muchos casos, no tenemos etiquetas que nos digan “esto es raro”. Ahí es donde entra el aprendizaje no supervisado. En este artículo se emplea un autocodificador, un tipo de red neuronal, para detectar patrones sospechosos sin necesidad de etiquetas, centrándonos en uno de los puntos más importantes (y subestimados): la elección del umbral.
Autocodificador
Un autoencoder es una red neuronal que se entrena para copiar sus entradas. Comprime la información en una capa intermedia (el espacio latente) y luego intenta reconstruirla.
La lógica es simple pero poderosa: si el modelo ha visto muchos ejemplos «normales», aprenderá a reconstruirlos bien. Pero si ve algo extraño, su reconstrucción será mucho peor. Esa diferencia entre el dato original y su reconstrucción se llama error de reconstrucción. Error que se puede calcular utilizando distintas funciones de perdida, como son el caso del error cuadrático medio (mse) o la distancia de Mahalanobis, que tiene en cuenta la correlación entre las variables.
Detección de datos anómalos
La detección de anomalías se basa en identificar patrones «inusuales», pero ¿cómo definimos lo «demasiado raro»? La clave está en establecer un umbral (threshold) que actúe como frontera entre lo normal y lo anómalo.
La selección del umbral no es única y depende del contexto. Algunas estrategias comunes:
- Percentiles estadísticos
- Usar percentiles (ej. 95% o 99%) del error de reconstrucción en datos normales. Todo lo que supere ese valor se considera anomalía.
- Validación con datos etiquetados (si están disponibles)
- Usar un subconjunto con anomalías conocidas para calibrar el umbral que maximice métricas como precisión o recall.
Ejemplo detección de anomalías en drones
Para el siguiente ejemplo, se utiliza el conjunto de datos: https://www.kaggle.com/datasets/luyucwnu/tlmuav-anomaly-detection-datasets, desarrollando un autocodificiador y empleando la distancia de Mahalanobis junto con la defnición de un umbral utilizando percentiles con el fin de estimar un funcionamiento anómalo.
La distribución de los datos se puede comprobar en la siguiente imagen, donde aparecen representados los datos t-SNE (t-Distributed Stochastic Neighbor Embedding):
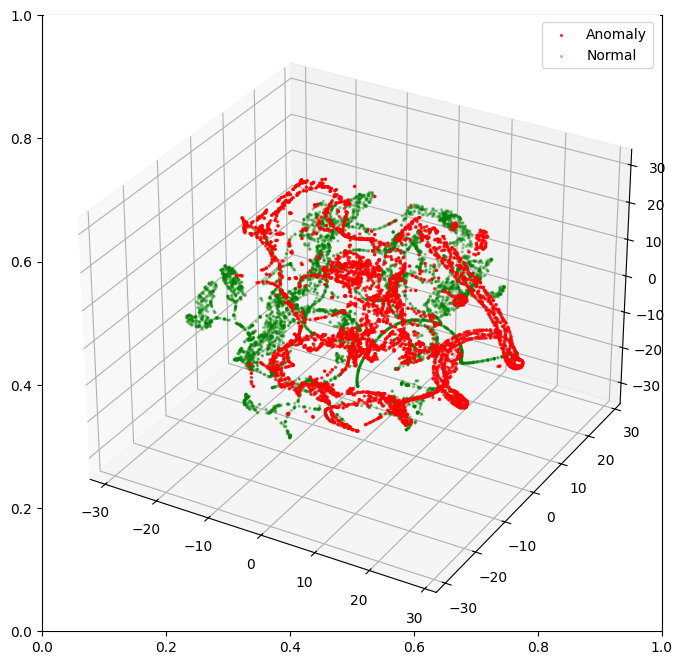
A partir de estos datos, se entrena un autocodificar con los datos normales, utilizando la siguiente estructura:
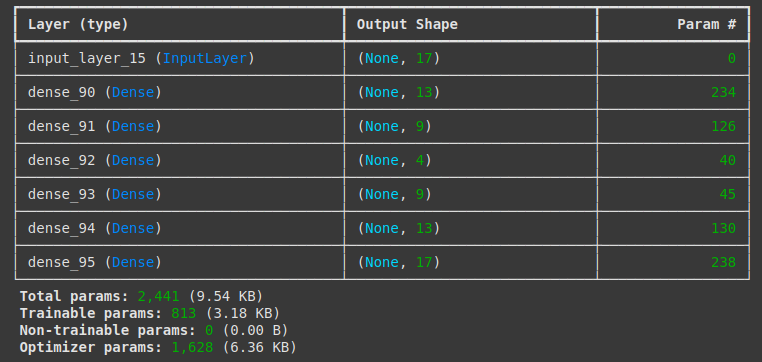
El autocodificador aprende a generar un espacio latente con la información comprimida:
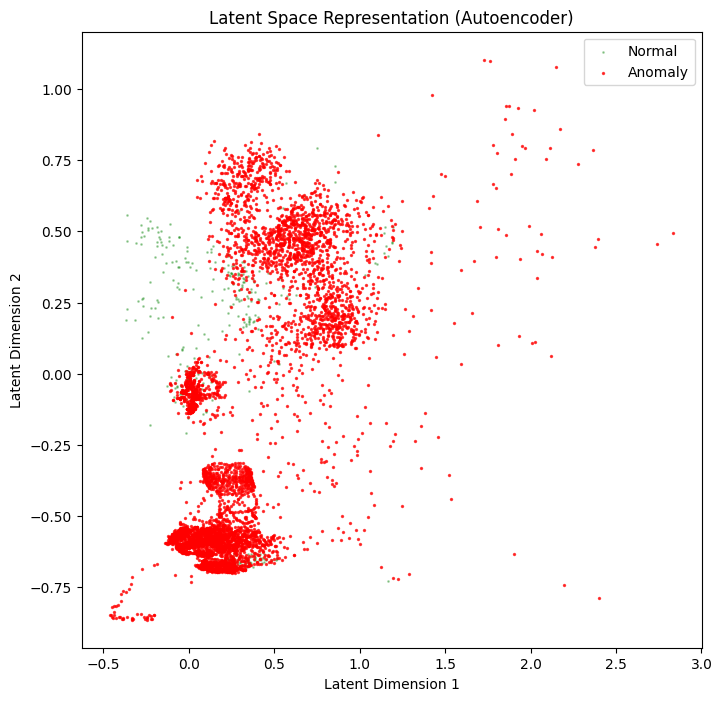
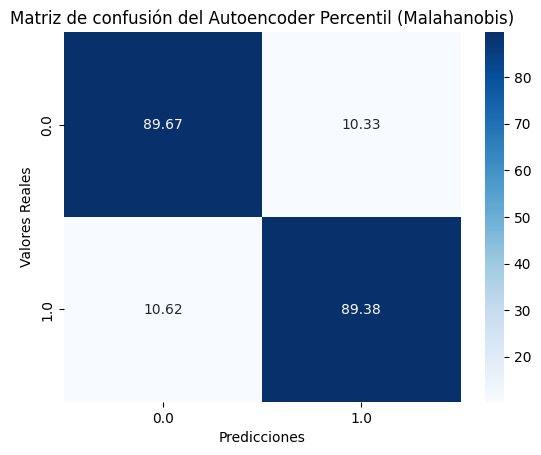
A partir del error generado y se utiliza el percentil 90 como umbral para detectar anomalías:
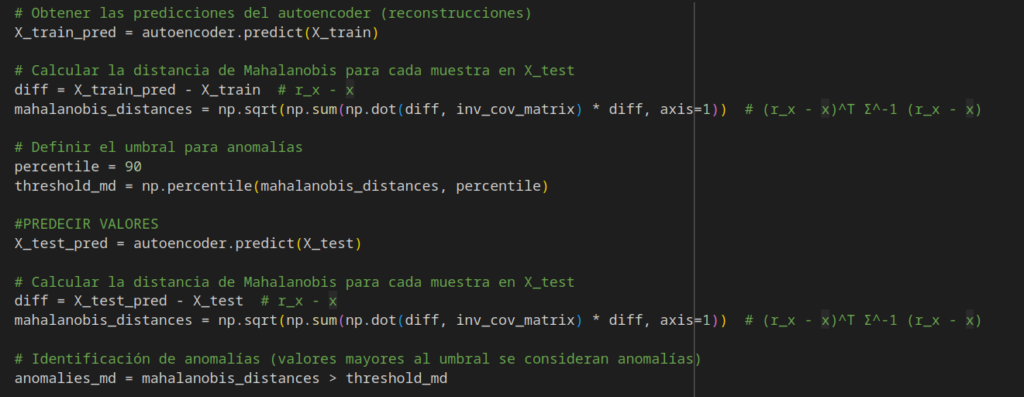
Al evaluar el modelo con datos que contienen anomalías, se observa que el umbral seleccionado permite al sistema detectar una buena parte de los eventos anómalos, sin comprometer en exceso la detección del comportamiento normal. Esto sugiere que el modelo logra un equilibrio razonable entre sensibilidad y precisión.
Conclusiones
Este experimento demuestra cómo los autocodificadores pueden convertirse en una herramienta eficaz para la detección de anomalías cuando no se dispone de datos etiquetados. Al entrenarse únicamente con ejemplos normales, el modelo aprende a reconstruir patrones habituales, y cualquier desviación significativa en la reconstrucción puede interpretarse como una señal de comportamiento anómalo.
Aplicado a un contexto concreto como la monitorización de drones, el modelo muestra una buena capacidad para identificar eventos anómalos sin comprometer en exceso la detección de funcionamiento normal. Esto refuerza el valor de los autocodificadores como una solución ligera y versátil para tareas de vigilancia automatizada, especialmente en entornos donde los datos etiquetados son escasos o inexistentes.
En definitiva, la detección de anomalías no es solo cuestión de algoritmos complejos, sino de comprender bien los datos, diseñar soluciones interpretables, y tomar decisiones correctas en cada etapa del proceso.