
En el contexto del mantenimiento predictivo, la detección de anomalías mediante aprendizaje supervisado ha emergido como una técnica eficaz para anticipar fallos en equipos industriales. A diferencia de los enfoques no supervisados, este método aprovecha datos etiquetados para entrenar modelos que distinguen con precisión entre condiciones normales y anómalas.
Tipos de Anomalías en Entornos Industriales
Las anomalías pueden manifestarse de distintas formas, cada una requiriendo estrategias de detección especializadas:
Clasificación de Anomalías
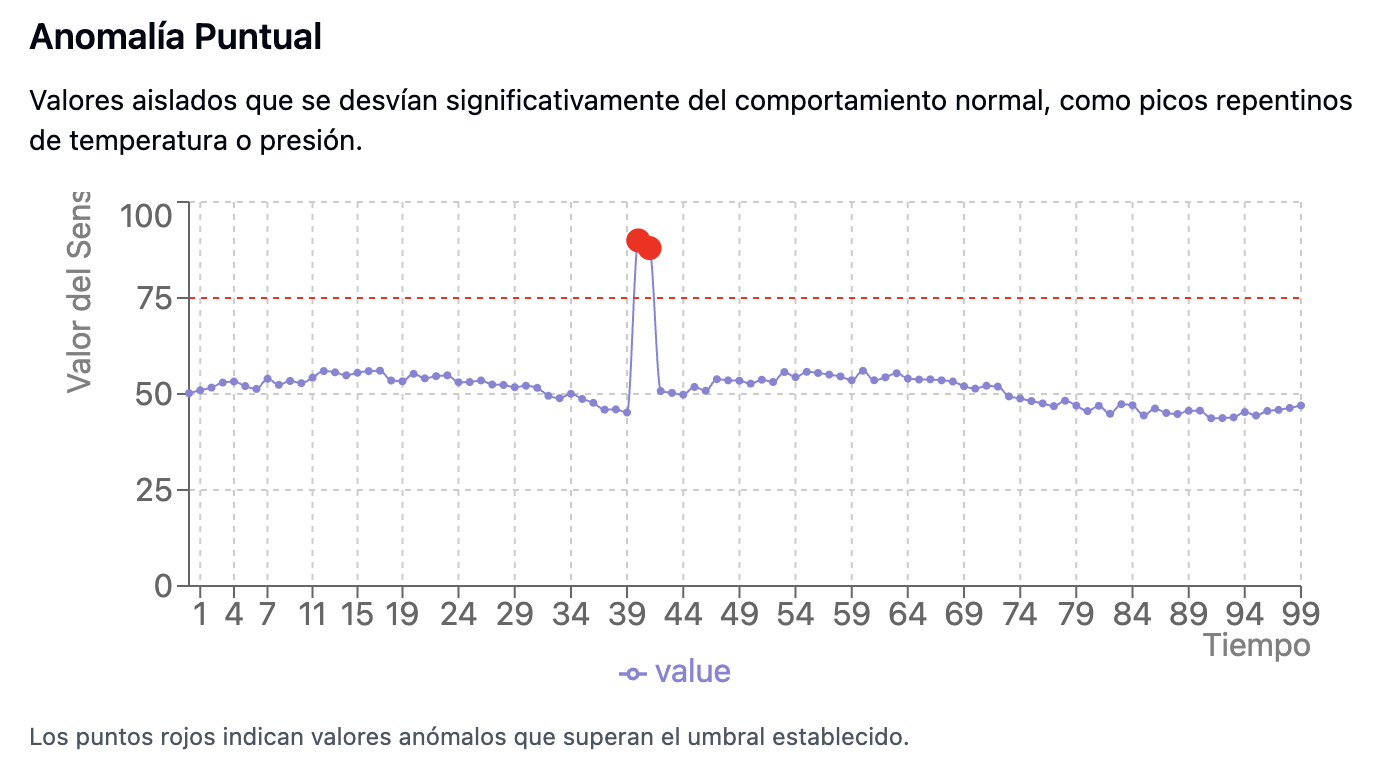
- Fácilmente detectables mediante métodos estadísticos como IQR o regresión simple.
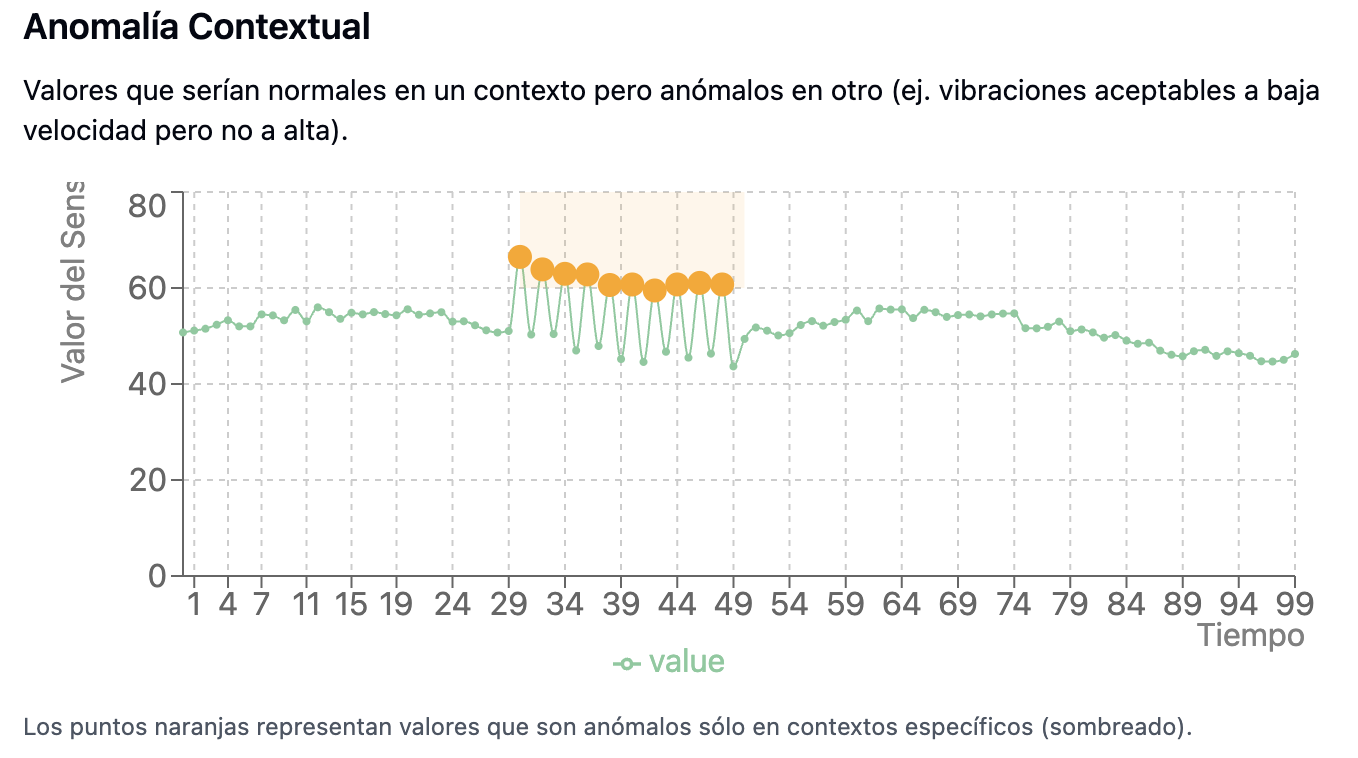
- Requieren modelos que capturen la relación entre variables, como temperatura versus carga.
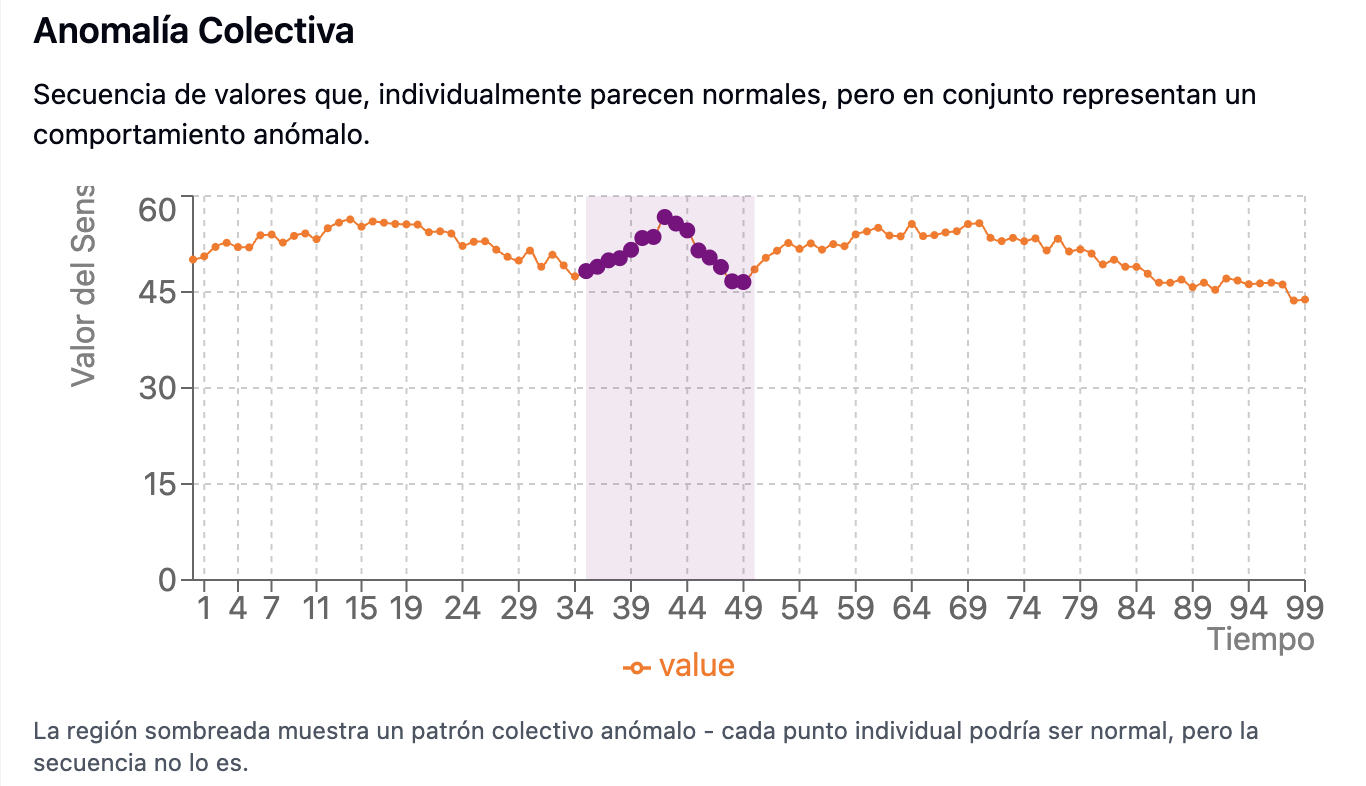
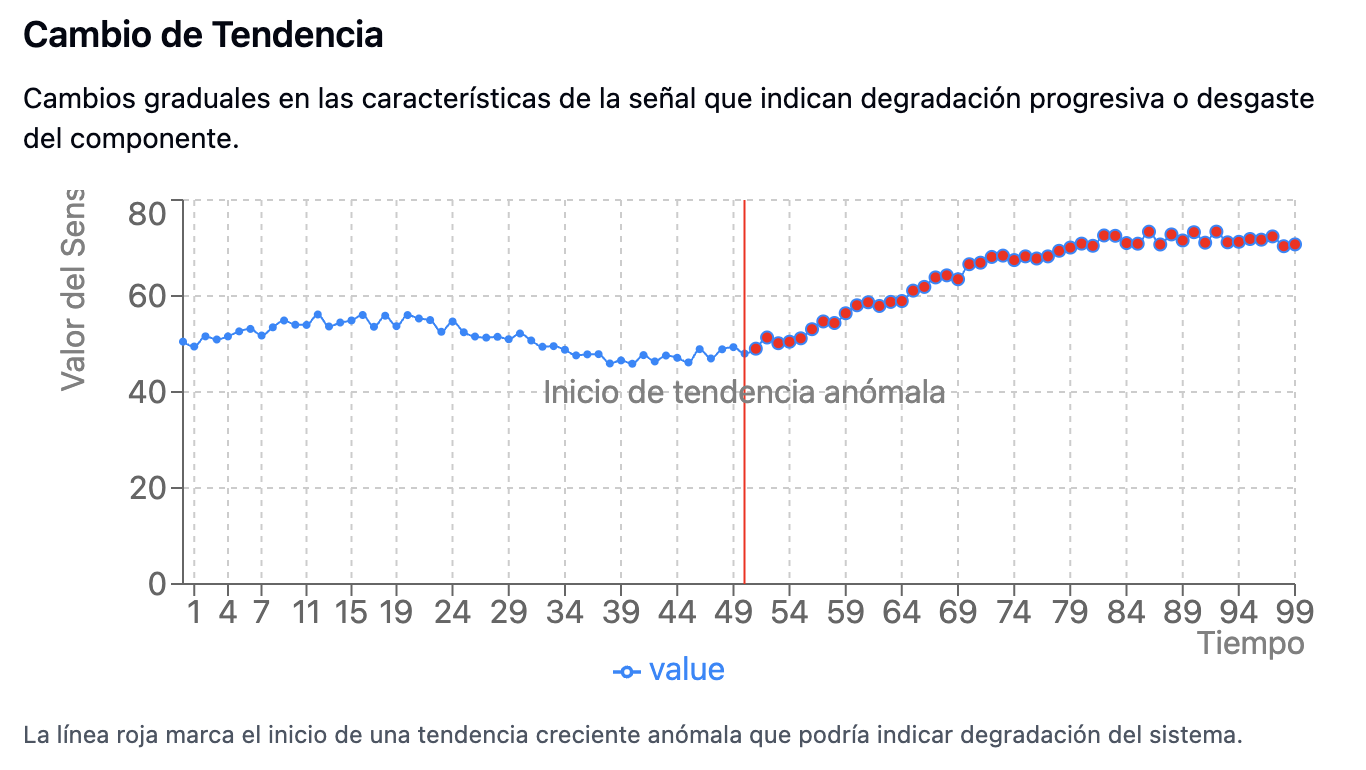
- Más sutiles, requieren ingeniería de características como pendientes móviles o transformadas de frecuencia.
- Estructura de Datos: Un dataset típico para esta tarea podría lucir así:

Entradas:
- Mediciones de sensores (temperatura, presión, vibración, corriente)
- Variables operativas (velocidad, carga)
- Variables derivadas (gradientes, estadísticas móviles, FFT)
Salidas:
- Clasificación binaria: Normal vs. Anómalo
- Clasificación multiclase: tipos de fallos
- Clasificación jerárquica: categoría y subcategoría del fallo
Etiquetado:
- Expertos humanos
- Umbrales definidos por normativa
- Simulaciones validadas
Modelos Supervisados para Detección de Anomalías
1. SVM (Support Vector Machines)
Las SVM con kernels no lineales permiten modelar fronteras de decisión complejas:
from sklearn.svm import OneClassSVM
model = OneClassSVM(kernel='rbf', gamma=0.1, nu=0.01)
model.fit(X_train)
anomaly_scores = model.decision_function(X_test)2. Redes LSTM con Mecanismos de Atención
Permiten detectar patrones temporales relevantes en secuencias largas:
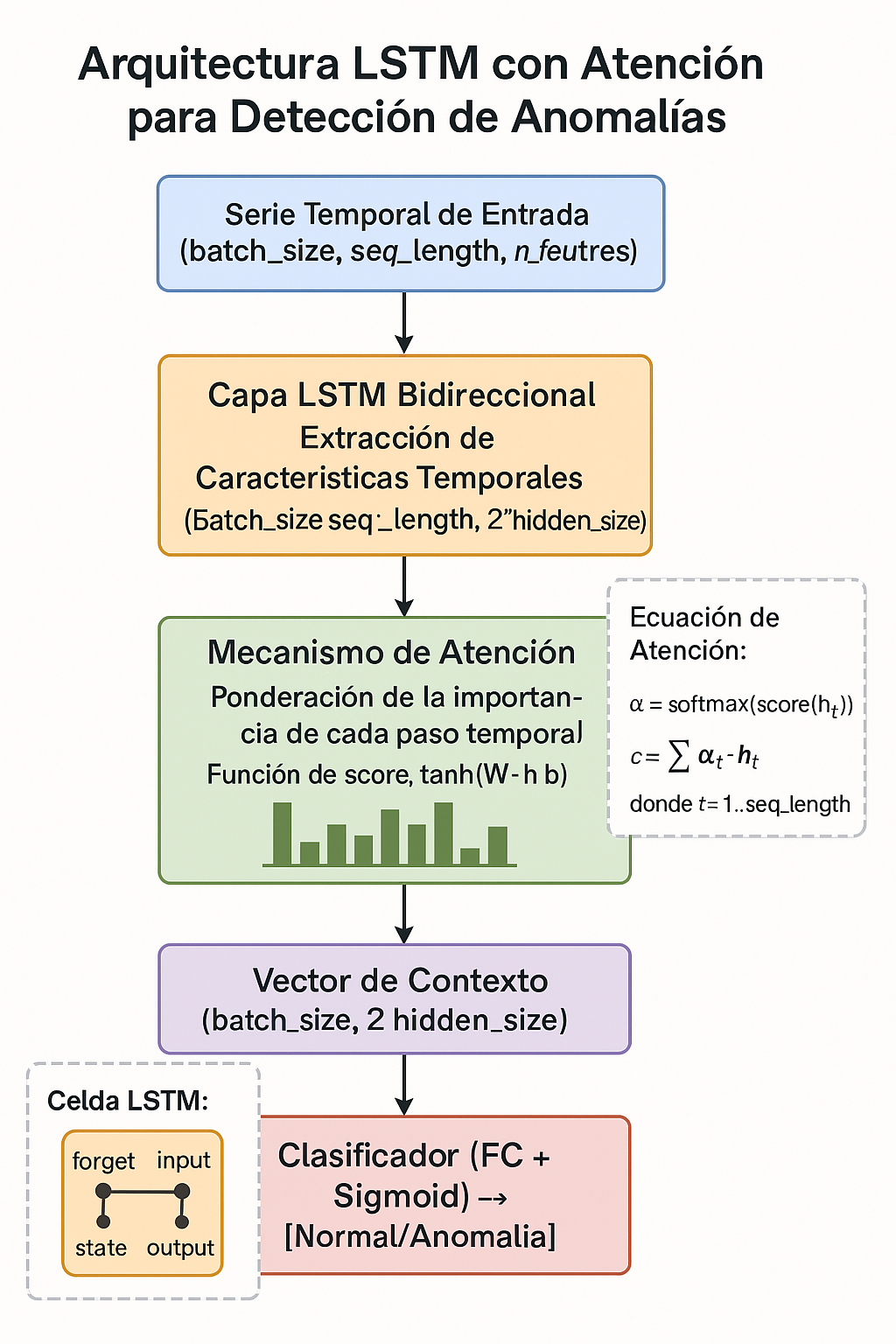
Componentes clave:
- Entrada: Secuencia multivariada
(batch_size, seq_length, n_features) - LSTM Bidireccional: Captura dependencias hacia adelante y atrás
- Atención: Asigna pesos a pasos temporales relevantes
- Vector de contexto: Resume la secuencia ponderada
- Clasificador: Capa final para salida binaria o multiclase
Ecuación de Atención
αₜ = softmax(score(hₜ))
c = ∑ αₜ ⋅ hₜLa suma ponderada mejora la interpretabilidad y rendimiento del modelo.
3. Gradient Boosting (XGBoost / LightGBM)
Ideales para datos desbalanceados, con soporte para ajuste de pesos por clase:
import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'auc',
'scale_pos_weight': 10
}
model = lgb.train(params, train_data)Métricas para Evaluación de Modelos
La evaluación debe considerar el desbalance y el costo de los errores:
- PR-AUC: Preferida sobre ROC-AUC en contextos desbalanceados
- Fβ-score: Permite ponderar el recall
- Matriz de confusión ponderada: Costos diferenciados por clase
Estrategias de Balanceo
- SMOTE: Sobremuestreo sintético
- Undersampling dirigido: Eliminación selectiva
- Pérdida ponderada: Ajuste en la función de costo
Transfer Learning para Análisis de Anomalías
Reutiliza modelos entrenados en dominios con muchos datos (Dominio A) para adaptarlos a entornos específicos (Dominio B) con pocos datos mediante ajuste fino.
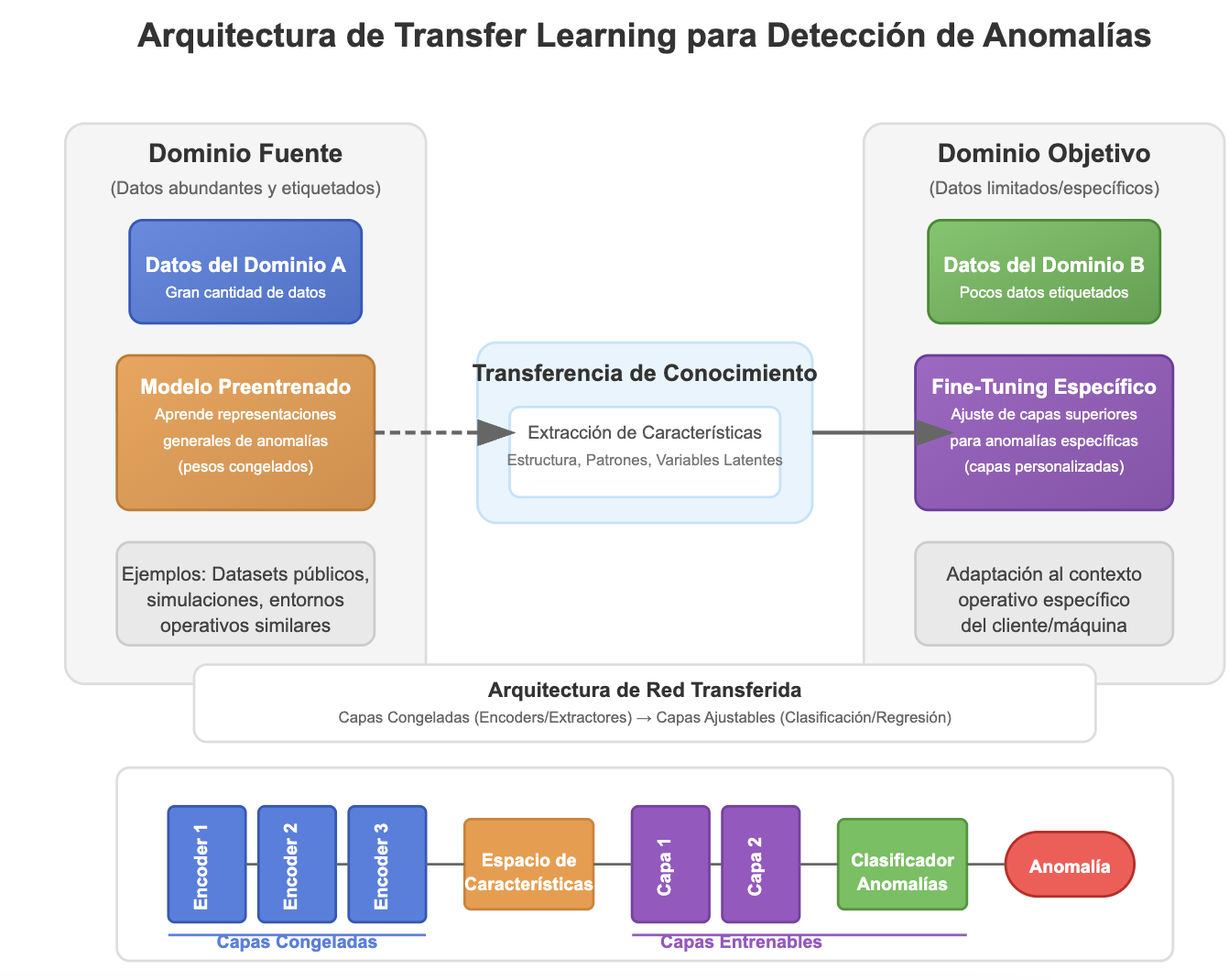
Ejemplo de fine-tuning de capas finales:
base_model = load_pretrained_industrial_model()
for layer in base_model.layers[:-3]:
layer.trainable = False
x = base_model.output
x = Dense(128, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x)
model = Model(inputs=base_model.input, outputs=predictions)Referencias
- Chandola, V., et al. (2009). Anomaly detection: A survey. ACM CSUR.
- Ruff, L., et al. (2021). A unifying review of deep and shallow anomaly detection. IEEE.
- Zhao, R., et al. (2019). Deep learning for machine health monitoring. MSSP.