
En el contexto de un proyecto reciente de análisis de datos de sensores de drones, me enfrenté a un desafío común en la ingeniería de datos y ML: la brecha entre el volumen de los datos brutos y los recursos de hardware disponibles. Este artículo detalla la transición técnica de un flujo de trabajo basado en Pandas y CSV a uno escalable utilizando Dask y Apache Parquet.
1. El Problema: Cuellos de Botella en Memoria y E/S
El objetivo era realizar procesos de ETL (Extracción, Transformación y Carga) y EDA (Análisis Exploratorio de Datos) sobre un dataset masivo de telemetría de drones. El flujo de trabajo inicial se basaba en la librería estándar pandas y archivos en formato .csv.
Rápidamente, se identificaron dos limitaciones críticas de hardware y software:
- Saturación de RAM (MemoryError): Pandas carga el dataset completo en memoria para operar. Con archivos CSV individuales que superaban 1 GB y un volumen total considerable, el consumo de RAM excedía la capacidad física de la máquina, provocando el cierre forzado del proceso o el uso excesivo de swap, degradando el rendimiento del sistema.
- Ineficiencia de I/O en CSV: La lectura de archivos CSV gigantescos es computacionalmente costosa debido a la necesidad de inferir tipos de datos y analizar texto plano fila por fila. Los tiempos de carga eran prohibitivos para una iteración ágil durante el EDA.
2. La Solución Técnica: Computación «Lazy» y Almacenamiento Columnar
Para mitigar estos problemas sin incurrir en costes de infraestructura en la nube, se reestructuró el pipeline basándose en dos cambios fundamentales:
A. De Pandas a Dask (Procesamiento)
Se sustituyó Pandas por Dask DataFrames. A diferencia de la ejecución inmediata de Pandas, Dask utiliza evaluación perezosa.
- Impacto: Esto permitió definir transformaciones complejas sobre el dataset completo sin cargarlo en memoria. Dask procesa los datos en chunks (fragmentos) secuenciales, utilizando el disco duro como respaldo y liberando la memoria una vez que el fragmento ha sido procesado.
B. De CSV a Parquet (Almacenamiento)
El cambio más significativo en rendimiento provino de migrar el almacenamiento de .csv a .parquet.
- Compresión y Eficiencia: Parquet es un formato binario de almacenamiento en columnas. Al realizar el EDA, a menudo solo necesitamos acceder a columnas específicas (ej.
altitud,velocidad). Parquet permite leer solo esas columnas sin escanear el archivo entero, reduciendo drásticamente las operaciones de E/S.
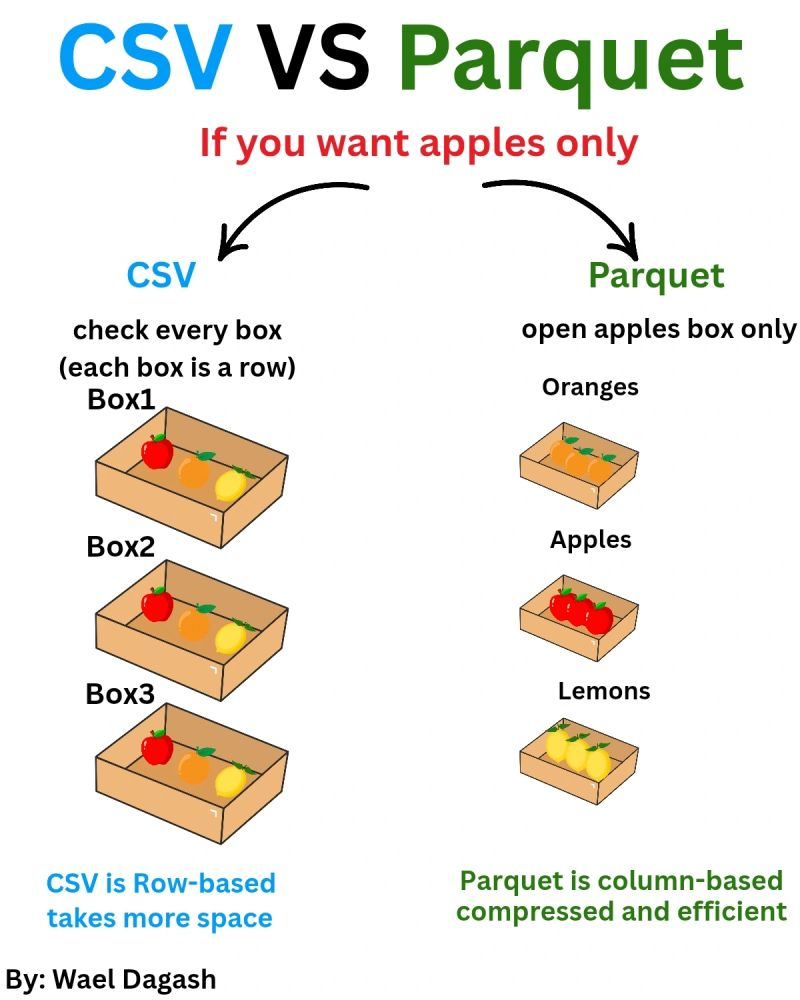
- Particionado: Se dividieron los archivos CSV en múltiples particiones
.parquet. Esto facilitó que Dask pudiera paralelizar la lectura y el procesamiento utilizando múltiples núcleos de la CPU simultáneamente.
3. Análisis Crítico de la Implementación
Como ingeniero, es vital evaluar no solo las ventajas, sino también las fricciones introducidas por esta solución.
Ventajas (Pros):
- Viabilidad: Hizo posible trabajar con un dataset que simplemente no se podía abrir anteriormente debido a las limitaciones de HW.
- Velocidad de Lectura: Una vez convertidos los datos a Parquet, las operaciones de lectura subsiguientes para el EDA fueron exponencialmente más rápidas que con CSV.
- Tipado Estricto: Parquet preserva los metadatos de los tipos de datos, eliminando los errores comunes de inferencia de tipos que ocurren al leer CSVs.
Desventajas y Fricciones (Contras):
- Coste Inicial de Conversión: El proceso de convertir los CSV originales a Parquet fue lento y requirió un script de ETL dedicado solo para esta tarea.
- Pérdida de Legibilidad Humana: A diferencia de un CSV, los archivos Parquet son binarios y no pueden inspeccionarse rápidamente con un editor de texto simple, lo cual complica verificaciones rápidas visuales.
- Complejidad de Depuración: Los errores en Dask a menudo no saltan hasta que se ejecuta
.compute(), lo que hace que el stack trace sea más difícil de interpretar que en Pandas.
Conclusión
La adopción de Dask y Parquet no fue una preferencia, sino una necesidad de ingeniería impuesta por las restricciones de hardware. Para datasets que caben en la RAM, Pandas sigue siendo superior por su simplicidad y velocidad inmediata. Sin embargo, cuando los datos escalan más allá de la memoria local, la combinación de Dask para el cómputo distribuido y Parquet para el almacenamiento eficiente es un estándar de la industria robusto y necesario.
Referencias
[1] W. Dagash, «Data Engineering: Parquet vs CSV performance comparison,» LinkedIn Post, 2025. [Online]. Disponible: https://www.linkedin.com/posts/wael-dagash-48692b120_dataengineering-parquet-csv-activity-7315237295220043776-1L_5/.