
Imagina que eres un técnico de campo frente a una turbina industrial que emite un sonido extraño. Tienes un iPad con 500 manuales en PDF, cada uno de 300 páginas. Buscar la solución manualmente es como buscar una aguja en un pajar mientras el tiempo (y el dinero) corre.
Aquí es donde entra el RAG (Retrieval-Augmented Generation). En lugar de que el técnico lea todo el PDF, el sistema lo hace por él, extrayendo la instrucción precisa. Pero, ¿cómo pasa un PDF estático a ser una base de conocimiento «viva»?
Todo se resume en dos fases críticas: Indexado (preparar la información) y Retrieval (encontrar la respuesta).
Fase 1: Indexado (Construyendo la biblioteca digital)
El indexado es el proceso de transformar tus manuales de mantenimiento en un formato que una Inteligencia Artificial pueda «entender» y buscar rápidamente. No basta con subir el archivo; hay que desmenuzarlo.
1. Extracción y Limpieza (Parsing)
Los PDFs de mantenimiento son complicados: tienen tablas de torque, diagramas de despiece y advertencias de seguridad en negrita. En esta etapa, convertimos el PDF en texto plano o Markdown.
Nota técnica: Es vital usar herramientas de OCR o librerías que respeten la estructura de las tablas, ya que un valor de presión mal leído puede causar un fallo crítico.
2. Segmentación (Chunking)
Un modelo de lenguaje no puede leer 300 páginas de una sola vez para responder una duda. Dividimos el texto en fragmentos pequeños o chunks.
- Estrategia: En mantenimiento, usamos fragmentos con «solapamiento» (overlap). Si cortamos una instrucción a la mitad, el sistema podría perder el contexto de seguridad.
3. Generación de Embeddings
Aquí ocurre la magia. Cada fragmento de texto se pasa por un modelo matemático que lo convierte en un vector (una lista de números). Estos números representan el significado semántico del texto.
- Si el texto dice «ajuste de válvula» y otro dice «calibración de regulador», sus vectores estarán cerca en el espacio matemático porque significan algo similar.
4. Vector Database (El almacén)
Guardamos esos vectores en una base de datos especializada (como Pinecone, Milvus o Weaviate). Ya no buscamos por «palabras clave», sino por conceptos.
Fase 2: Retrieval (La búsqueda inteligente)
Una vez que nuestra biblioteca está indexada, el sistema está listo para trabajar. Cuando el técnico hace una pregunta, se activa el proceso de recuperación o Retrieval.
1. Vectorización de la consulta
Si el técnico pregunta: «¿Cuál es el par de apriete para los pernos de la carcasa?», el sistema convierte esa pregunta en un vector usando el mismo modelo de embeddings que usamos en la fase de indexado.
2. Búsqueda de Similitud
El sistema compara el vector de la pregunta con los millones de vectores que tenemos en nuestra base de datos. Para medir qué tan «cerca» están, solemos usar una fórmula llamada Similitud del Coseno:
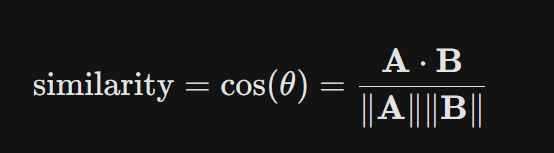
El sistema selecciona los 3 o 5 fragmentos (chunks) que más se parecen a la duda del técnico.
3. Contextualización y Respuesta
Aquí es donde el sistema «le pasa la nota» al LLM (como GPT-4 o Claude). En lugar de preguntarle a la IA qué sabe sobre pernos, le enviamos un prompt como este:
«Basándote exclusivamente en estos 3 fragmentos del manual de la turbina X-200, responde: ¿Cuál es el par de apriete para los pernos de la carcasa?»
El resultado es una respuesta precisa, fundamentada en el manual real y no en una alucinación de la IA.
¿Por qué esto cambia las reglas del juego en mantenimiento?
- Reducción del MTTR (Mean Time To Repair): El técnico no pierde 20 minutos buscando en un índice.
- Seguridad mejorada: El sistema puede priorizar fragmentos que contengan advertencias de «PELIGRO» relacionadas con la tarea.
- Transferencia de conocimiento: Los técnicos novatos tienen acceso a la sabiduría de décadas de manuales de forma instantánea.
Conclusión
El éxito de un sistema RAG en entornos industriales no depende de qué tan «inteligente» sea el modelo de lenguaje, sino de qué tan bien hayamos ejecutado el indexado y qué tan preciso sea nuestro retrieval. Si los datos están bien organizados y la búsqueda es fina, habrás convertido tus PDFs olvidados en el asistente más valioso de tu equipo técnico.