
En la era de la Inteligencia Artificial, la pregunta ya no es qué puede hacer la IA por nosotros, sino dónde viven nuestros datos mientras lo hace. Para muchas empresas y entusiastas, subir manuales técnicos o documentos sensibles a la nube de un tercero no es una opción.
Hoy vamos a desglosar cómo montar un sistema de Generación Aumentada por Recuperación (RAG) totalmente local, utilizando una arquitectura robusta que permite «chatear» con tus propios documentos sin que ni un solo bit salga de tu red.
El «Stack» Tecnológico: Privacidad por Diseño
Para este proyecto, hemos desplegado un ecosistema basado en contenedores Docker, lo que garantiza que todo el software esté aislado y sea fácil de replicar. Los protagonistas son:
- Flowise: Nuestra interfaz low-code para orquestar el flujo.
- Ollama: El motor que corre los modelos de lenguaje (LLMs) localmente.
- ChromaDB: Nuestra base de datos vectorial para «recordar» el contenido de los archivos.
Anatomía del Flujo: De un PDF a una Respuesta Inteligente
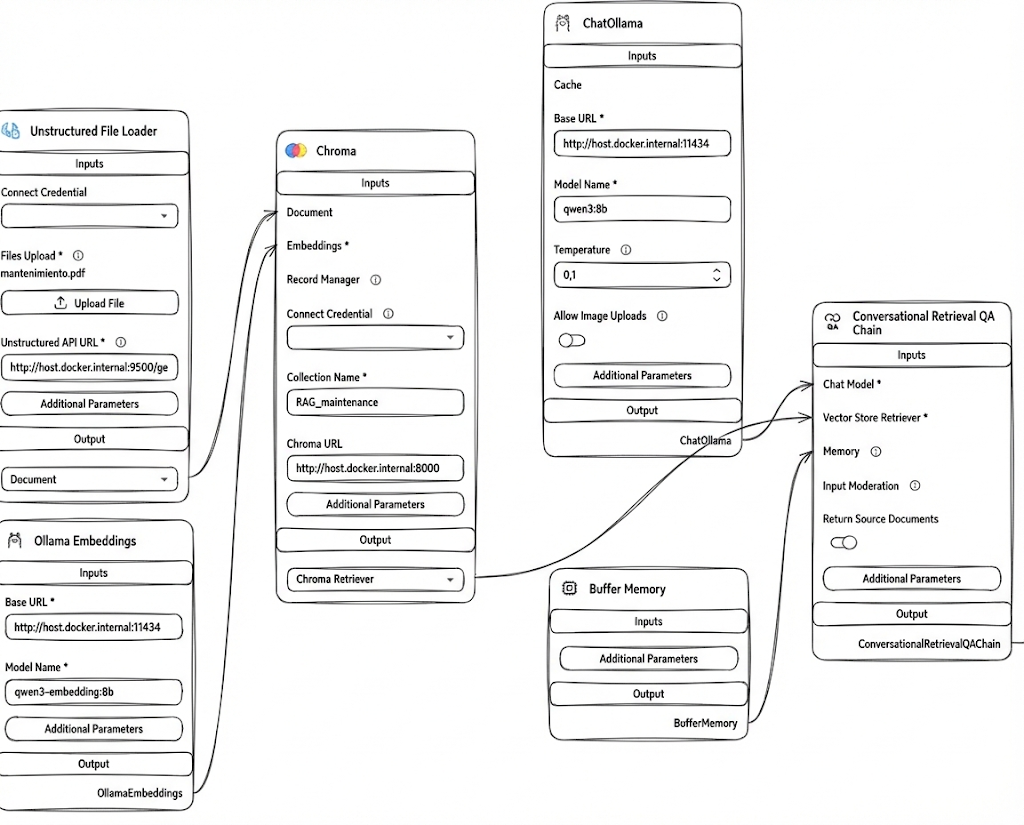
Si observamos el esquema que hemos diseñado en Flowise, podemos dividir el proceso en tres fases críticas:
1. La Ingesta de Conocimiento
Todo empieza con el Unstructured File Loader. En este caso, estamos alimentando al sistema con un archivo llamado mantenimiento.pdf.
Este documento no se lee como un texto simple; se procesa a través de Ollama Embeddings (usando el modelo qwen3-embedding:8b). Lo que hace este componente es traducir el texto humano a vectores matemáticos que la máquina puede «entender» contextualmente.
2. El Almacenamiento en Chroma
Una vez que el PDF está vectorizado, se guarda en Chroma. Piensa en esto como una biblioteca ultraeficiente donde los libros no están ordenados por título, sino por «significado». Hemos nombrado a esta colección RAG_maintenance. Gracias a que usamos Docker, la conexión se realiza internamente a través de http://host.docker.internal:8000.
3. El Cerebro: Qwen3 y la Cadena de Retención
Cuando el usuario hace una pregunta, entra en juego el ChatOllama con el modelo qwen3:8b. Pero no responde al azar:
- Conversational Retrieval QA Chain: Es el director de orquesta. Recibe la pregunta, busca la información relevante en Chroma y se la entrega al modelo
qwen3. - Buffer Memory: Permite que la IA recuerde lo que dijimos hace tres mensajes, haciendo que la interacción se sienta como una conversación real y no como comandos aislados.
¿Por qué esta configuración es un «Game Changer»?
Lo más interesante de este flujo es el uso de los modelos Qwen3. Desarrollados para ser extremadamente eficientes, permiten obtener respuestas de alta calidad incluso en hardware local, sin necesidad de GPUs industriales de miles de dólares.
Además, al usar la dirección host.docker.internal, estamos permitiendo que los diferentes contenedores (el de Flowise, el de Ollama y el de Chroma) se hablen entre sí de forma transparente, creando un ecosistema sólido y escalable.
Conclusión
Implementar un sistema RAG local no solo es un ejercicio técnico fascinante, es una declaración de soberanía de datos. Ya sea para consultar manuales de mantenimiento (como en nuestro ejemplo) o para analizar bases de conocimiento internas, este esquema en Flowise demuestra que la IA potente y privada ya está al alcance de un docker-compose up.