
Los Normalizing Flows son un tipo de Probabilistic Generative Model, esto significa que lo que buscamos simular con el modelo es la distribución de una variable X, usando los datos que tenemos (xi), describiéndola con una función de densidad pX(x) y que además es parametrizado por un valor θ.
La idea principal de este modelo es sencilla: queremos encontrar una función f de tal manera que f : X → Z donde Z es el espacio de ruido gaussiano. Con esto, conseguimos que f (x) = z nos de un ruido gaussiano. Esta función ha de ser invertible y diferenciable, lo que permite que luego a raiz de ruido gaussiano aleatorio, podamos implementar la inversa de esta función y generar datos que provienen de la misma distribución que los reales, y por tanto se parezcan a ellos. Podemos usar la función de cambio de variables para escribir la función de densidad pX(x), en función de nuestra transformación f y nuestro espacio Z como:
pX (x) = pZ (f (x))*|det Df (x)|
Tenemos una serie de Requisitos de f que necesitamos que se cumplen para poder calcular pX de esta manera:
- Invertible: Existe f−1.
- Diferenciable: Para poder calcular el jacobiano Df(x).
- Eficiente: Cálculo rápido de f−1 y detDf(x).
Como en todo problema de optimización, debemos de fijar la función de coste que buscamos maximizar, en este caso esta función es:
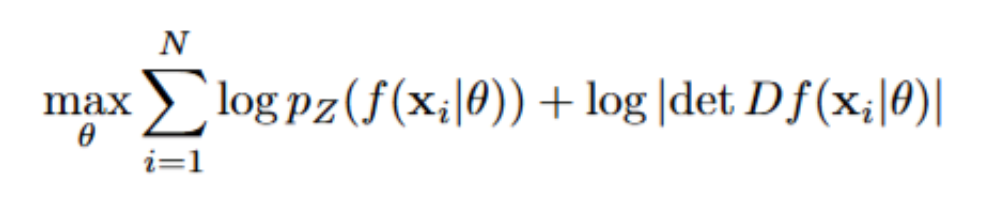
Para construir esta función f (normalmente a la que se refiere como el Flow), lo que se suele hacer es escribirla como una composición de funciones: f=fK∘⋯∘f1, donde cada fk es invertible, diferenciable y eficiente, lo que nos asegura que la composición: f también lo sea, además de ello, el jacobiano total es el producto de los jacobianos individuales:
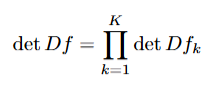
Lo que permite el calculo eficiente de la función que buscamos maximizar
Sobre estas funciones diferentes tipos que podemos implementar, las mas comunes son:
- Lineales/Afines: f(x)=Ax+b
- Son funciones fáciles, intuitivas y sencillas de implementar, pero solo pueden ajustar la media y la varianza de la función, por lo que no incluyen gran complejidad.
- Autoregresivos: f(xi)=μi(x1:i−1)+σi(x1:i−1)⋅xi
- Están descritas de una manera en la que el valor del siguiente punto transformado en el vector depende de los anteriores, esto permite introducir secuencialidad y crear modelos mas complejos, a cambio de un coste computacional mayor.
- Coupling Flows: f(x)=(xA,f^(xB∣θ(xA))).
- Consiste primero en dividir el set de datos x en dos subsets xA y xB, Solamente se transforman los datos de xB , pero esto se hace de tal manera que los parámetros de estas transformaciones dependan de xA, esto lleva a que se incluya mas complejidad y se establezcan relaciones entre los datos.
Para la generación de datos el método es simple:
- Se obtiene un elemento z cualquiera del espacio Z, distribuciones de ruido gaussiano
- Se calculala función f^-1(z), que es la conjugación de las inversas: f=f^-11∘⋯∘f^-1K
- Se aplica f^-1(z) y se obtiene un dato x´ el cual se asemejará a los datos usados para entrenar el modelo, ya que proviene de la misma distribución
De esta manera podemos generar grandes cantidades de datos sintéticos a raíz de un buen modelo de Normalizing Flows. Para aquellos atento al blog es posible que este tipo de modelos os hayan recordado a los Modelos de Difusión. En verdad son dos modelos similares, de generación de datos desde el ruido, sin embargo tienen una diferencia principal: los Normalizing Flows permiten calcular la función de densidad explícitamente, los modelos de Difusión lo hacen implícitamente, y no se preocupan por calcular esta función, si no de usarla para obtener los datos que se buscan.
Como veis no paramos de trabajar y de mostrar nuevos modelos útiles para la generación de datos, continuad atentos al blog!