
En nuestras publicaciones anteriores, hemos explorado cómo modelos como las Redes Neuronales Recurrentes (RNNs) y sus evoluciones, como las GRUs y LSTMs, nos permitieron trabajar con datos secuenciales, recordando información a lo largo del tiempo. Sin embargo, estas arquitecturas tienen sus limitaciones, especialmente cuando intentamos procesar secuencias muy largas o paralelizar el entrenamiento de estas de manera eficiente.
Aquí es donde entran en juego los Transformers. Presentados en el artículo «Attention Is All You Need» (Vaswani et al., 2017), los Transformers cambiaron las reglas del juego. dejan de depender de la secuencialidad de los RNN, lo cual le permitió ser capaz de capturar relaciones complejas a largo plazo, y, si bien al inicio se aplicaron en NLP, en los últimos años se han implementado con éxito en muchos otros dominios.
¿Por Qué Abandonar la Secuencialidad?
La principal desventaja de las RNNs es que procesan la información palabra por palabra, paso a paso. Esto crea un «cuello de botella» computacional y dificulta que el modelo conecte información relevante que se encuentra muy separada en la secuencia (el famoso problema de las dependencias a largo plazo).
Los Transformers rompen con esto. Procesan la secuencia completa de una vez. Pero si no procesan secuencialmente, ¿cómo saben el orden de las palabras? Y, lo más importante, ¿cómo relacionan una palabra con otra que podría estar muy lejos en la frase? La respuesta está en dos ideas clave: Codificación Posicional y Mecanismos de Atención.
Codificación Posicional
Dado que el Transformer procesa la secuencia completa simultáneamente, pierde la información sobre la posición de cada elemento (cada palabra o «token»). Para solucionar esto, antes de que la red vea los datos, se les añade una información extra a sus representaciones (embeddings): la Codificación Posicional (Positional Encoding).
Imagina que al «vector» que representa una palabra, le sumamos otro vector que codifica su posición dentro de la frase. El Transformer original utiliza funciones matemáticas (senos y cosenos de diferentes frecuencias) para generar estos vectores de posición. La magia de usar senos y cosenos es que no solo le dan una «identidad» única a cada posición, sino que también permiten que el modelo aprenda a reconocer la distancia relativa entre diferentes posiciones. De esta forma, el modelo sabe que «el coche rojo» se refiere a un coche específico, en parte porque «rojo» viene justo después de «coche», una relación que se aprende a través de esta codificación posicional.
Mecanismos de atenciñ
Si la codificación posicional le dice al Transformer dónde está cada palabra, el mecanismo de atención le dice cuál otra palabra de la secuencia es relevante para entender la palabra actual. Esta es la verdadera innovación.
Piensa en la atención como un proceso de «búsqueda y recuperación»:
- Cada palabra tiene una Query (Consulta): ¿Qué información estoy buscando?
- Cada palabra tiene una Key (Clave): ¿Qué información ofrezco?
- Cada palabra tiene un Value (Valor): La información real asociada si mi clave coincide con la consulta.
El Transformer calcula la «similitud» entre la Query de una palabra y las Keys de todas las demás palabras en la secuencia (incluida ella misma). Esta similitud se mide típicamente con un producto escalar. Luego, aplica una función (softmax) para convertir estas similitudes en pesos o probabilidades: ¿cuánta atención debo prestarle a cada otra palabra? Finalmente, combina los Values de todas las palabras, ponderados por estos pesos de atención. El resultado es una nueva representación para la palabra actual, enriquecida con información relevante de toda la secuencia.
La fórmula central es conceptualmente simple:
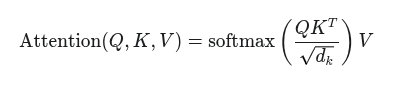
Donde QKT computa la similitud (consultas vs claves), se divide por un factor de normalización, softmax se utiliza para convertir la similitud a una probabilidad y se multiplica por V para finalmente obtener la combinación ponderada de los valores.
Atención Multi-Cabeza (Multi-head Attention)
En lugar de hacer este cálculo de atención una sola vez, los Transformers lo hacen varias veces en paralelo, usando diferentes conjuntos de «Queries», «Keys» y «Values» aprendidos. Esto es la Atención Multi-Cabeza. Cada «cabeza» de atención aprende a enfocarse en diferentes tipos de relaciones. Por ejemplo, una cabeza podría aprender a identificar sujetos de verbos, mientras que otra identifica adjetivos de sustantivos. Los resultados de todas las cabezas se combinan para obtener una representación mejor.
Atención Enmascarada (Masked Attention)
Cuando usamos un Transformer para generar secuencias palabra por palabra (como traducir o completar texto), necesitamos asegurarnos de que el modelo no «vea» las palabras futuras que aún no ha generado. Para esto, usamos la Atención Enmascarada. Aplicamos una «máscara» a las puntuaciones de similitud para que las palabras futuras tengan una puntuación de −∞. Cuando aplicamos softmax, estas puntuaciones se vuelven 0, impidiendo efectivamente que el modelo les preste atención. Esto es crucial en la parte del Decodificador del Transformer, asegurando que la generación sea causal (depende solo del pasado).
¿Por Qué Son Tan Efectivos?
Las ventajas de esta arquitectura basada en atención son notables:
- Captura de Dependencias a Largo Plazo: Al poder atender a cualquier otra posición directamente, superan fácilmente las limitaciones de memoria de las RNNs en secuencias largas.
- Paralelización: El cálculo de atención se puede realizar en paralelo para toda la secuencia, lo que acelera enormemente el entrenamiento en hardware moderno (GPUs, TPUs).
- Interpretabilidad Parcial: Las matrices de atención a veces pueden dar pistas sobre qué partes de la entrada fueron más importantes para la salida del modelo.
El Alcance de los Transformers
Aunque nacieron para el lenguaje, la idea de procesar secuencias con atención y sin recurrencia ha demostrado ser increíblemente versátil. Hoy vemos Transformers aplicados exitosamente en:
- Generación de datos sintéticos: Creando trayectorias (como rutas de vuelo o degradación de baterías) o datos tabulares realistas.
- Análisis de series temporales: Modelando patrones complejos en datos secuenciales de tiempo.
- Visión por Computadora: Con modelos como Vision Transformers que procesan imágenes como si fueran secuencias de «parches».
- Audio: Procesando secuencias de audio.
Los Transformers y su mecanismo de atención han revolucionado el campo de la IA, ofreciendo una arquitectura potente, eficiente y flexible que sigue impulsando avances en una multitud de dominios. Son una prueba de cómo una idea fundamental (enfocarse en lo relevante) puede transformar la forma en que las máquinas entienden y generan datos secuenciales.