
En la entrada del blog: Modelos Basados en Datos para la generación de Datos Sintéticos presentábamos la técnica Synthetic Minority Over-sampling Technique (SMOTE) [1] como una técnica simple de creación de datos sintéticos basada en datos. En este artículo queremos presentar los primeros resultados y estudios que hemos hecho, al igual que los posibles futuros desarrollos de esta técnica.
Los datos que se han usado para llevar a cabo este primer estudio se obtienen del PHM08 Challenge Data Set [2], que contiene datos de turbinas sintéticas y diferentes sensores de ellas.
Hemos introducido SMOTE de dos maneras diferentes:
- SMOTE para la generación de datos intermedios
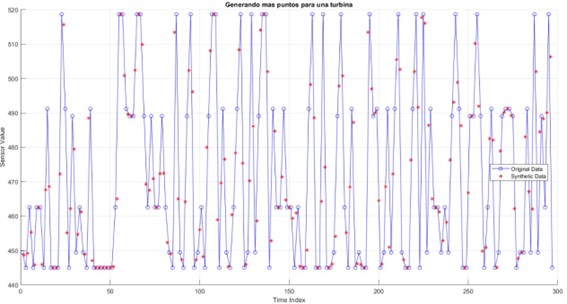
En este caso usamos dos puntos en la serie temporal para generar uno en medio de ellos, con esto conseguimos prácticamente duplicar el número de datos que tenemos de un sensor.
- SMOTE para la generación de turbinas sintéticas
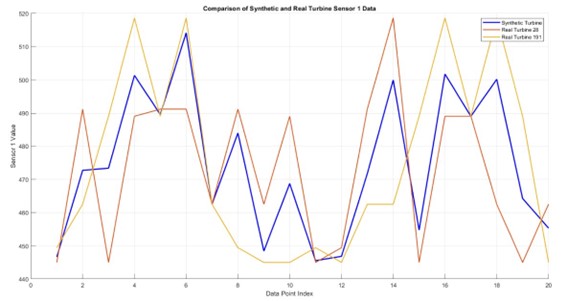
En este caso utilizamos dos turbinas sintéticas para generar una tercera, es importante resaltar que no tenemos información de los sensores de las turbinas, por lo que no sabemos si los datos de la turbina sintética generada tienen sentido, por eso hemos llevado a cabo un pequeño análisis de los datos sintéticos.
Análisis de los datos sintéticos
Este análisis se ha centrado en uno de los sensores de la turbina, y para cada una de las series temporales de ese sensor de las turbinas reales y las sintéticas hemos calculado estas variables:
- Media
- Varianza
- Deviación estándar
- Amplitud de la señal
- Número de picos en la señal
- Autocorrelación máxima
- Lag en la autocorrelación máxima
Una vez calculadas, podemos normalizar los datos y aplicar Principal Component Analysis (PCA) para observar los puntos en dos dimensiones:
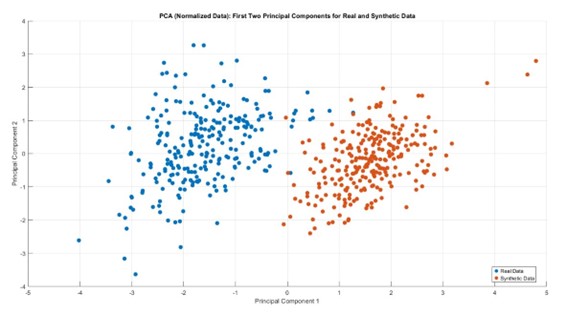
Esta imagen ya nos hace entender que parece que los datos sintéticos y reales son fácilmente distinguibles. De todas formas hemos llevado a cabo un par de algoritmos de clusterización no supervisados para confirmarlo:
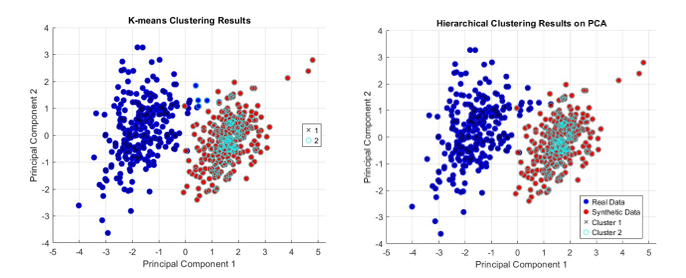
Ambos muestran que es fácil la distinción de datos reales y sintéticos, por lo que se necesita seguir investigando este método.
El trabajo para continuar mejorando la técnica SMOTE para generar datos sintéticos se basará en:
- Utilizar turbinas que se parezcan entre si para generar datos sintéticos
- Estudiar como crear datos sintéticos para las turbinas que tengan valores discretos (como es el caso del sensor mostrado en este ejemplo)
Manteneos atentos al blog para ver como evoluciona el proceso.
Referencias
[1] Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, 321-357.
[2] A. Saxena and K. Goebel (2008). «PHM08 Challenge Data Set», NASA Ames Prognostics Data Repository (http://ti.arc.nasa.gov/project/prognostic-data-repository), NASA Ames Research Center, Moffett Field, CA