
Continuando con los modelos de generación de datos sintéticos, hoy presentamos los denominados Algoritmos Genéticos. (GA)
La idea de estos algoritmos surge en la década de 1960 bajo la mano de John Holland
y continuó siendo refinado hasta que en 1975 presento el algoritmo definido en su libro [1]. Con los GA se busca reflejar la manera en la que funciona la evolución en la naturaleza: en una población, los individuos que mejor se adaptan al medio son los que sobreviven, y estos pasan su información genética a sus descendientes, además en la información genética de los descendientes pueden aparecer mutaciones que
hacen que se ajusten mejor ( o no ) al medio.
De esta manera, en GA los individuos que mejor cumplan la tarea de resolver el problema se usarán para generar nuevos individuos, al tener información de sus antepasados, estos nuevos individuos serán mejores a la hora de resolver el problema y se usarán para crear mejores descendientes hasta obtener un resultado.
De esta manera podemos definir el ADN de un individuo i como un vector⃗xi, donde
cada una de sus entradas xij hace referencia al gen j del individuo i . Un algoritmo
genético cuentan con 6 pasos:
- Seleccionar una población inicial al azar X donde cada individuo tiene su propio
ADN. - Seleccionar una función de aptitud F(x), de tal manera que podamos calcular como
de apto es cada ADN - Seleccionar los individuos más aptos, con respecto a F(x)
- Se lleva a cabo el Cruce de ADN: De tal manera que se generan a raiz de los
individuos mas aptos, nuevos ADNs que corresponden a nuevos individuos. - Se lleva a cabo la Mutación: En la que se introducen pequeños cambios en los
genes de estos nuevos individuos para incluir mas variedad genética. - Utilizando la función de aptitud y estos nuevos individuos se llevan a cabo los pasos
3-5 hasta obtener un resultado.
Para mayor claridad, explicamos como utilizar un algoritmo como este con un ejemplo: Salir de un laberinto.
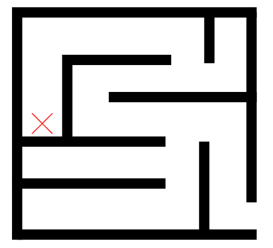
La figura muestra un ejemplo en el que se puede introducir este tipo de algoritmos.
Todos los individuos comienza en la cruz roja y su objetivo es salir del laberinto. Lo
individuos solo pueden moverse hacia arriba, abajo, derecha o izquierda, y podemos incluir mas normas, como que no pueden seguir moviéndose si se chocan con una pared. Con estas reglas, un individuo i tendría un ADN xi = (←, →,→, ↑, →, ↓, …) en el que cada gen describe el siguiente movimiento a hacer.
- Seleccionamos un número de individuos, por ejemplo 10, y a cada uno de estos le
asociamos su respectivo ADN. - Seleccionamos la función de aptitud F (x), en este caso podríamos contar como de
cerca nos hemos quedado de la salida. - Seleccionamos un número limitado de individuos más aptos (por ejemplo 3) con
respecto a F (x), es decir, los tres que se han quedado mas cercanos de la salida - Hacemos el cruce de ADN: De tal manera que utilizaríamos el ADN de los individuos mas aptos para generar individuos nuevos(por ejemplo, dividiendo en tres trozos los movimientos y eligiendo aleatoriamente de los 3 individuos un trozo para el nuevo individuo).
- Llevamos a cabo la mutación, en la que por ejemplo cada gen de los individuos tiene una posibilidad del 10% de cambiar a otro gen aleatorio.
- Utilizando la función de aptitud y estos nuevos individuos se llevan a cabo los pasos
3-5 hasta obtener un individuo que escapa del laberinto.
Cabe destacar las limitaciones de cada uno de estos pasos:
- Un número mayor de individuos llevará a encontrar a individuos mas aptos, pero
también requerirá un mayor tiempo de computación. - La función de aptitud tiene que ser elegida correctamente, si por ejemplo la elegimoscomo simplemente los individuos mas cercanos sin contar las paredes, es posible que los individuos se queden al otro lado de la pared del final.
- El número de individuos mas aptos trae consigo un dilema parecido al del número
1. - La manera en la que hacemos el cruce de ADN es importante también, si no lo
hacemos correctamente es posible que la información que se quiere conservar con
este cruce se pierda. - La mutación es un proceso necesario pero que tiene que ser ajustado correctamente. Si por ejemplo no hiciésemos mutación o el coeficiente fuese demasiado pequeño, si ninguno de nuestros individuos iniciales girase a la derecha en ningún momento, el problema no podría ser solucionado o tardaría mucho en solucionarse. Si elegimos un índice de mutación muy grande, la información que queremos conservar de los anteriores individuos se perdería .
Los algoritmos genéticos tienen muchas posibilidades para ser usados, el principal problema que tienen es que, aunque podemos describirlos con reglas generales, cada algoritmo será específico al problema que estamos resolviendo. Nuestro problema bien podría ser generar datos sintéticos que se parezcan a los reales, y tendríamos que describir correctamente cada uno de los pasos para llegar hasta el objetivo final.
Como veis os traemos algoritmos interesantes muy a menudo, no dejéis de estar atentos al blog!
Referencias:
[1]Holland, J. H. (1992). Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. MIT press.