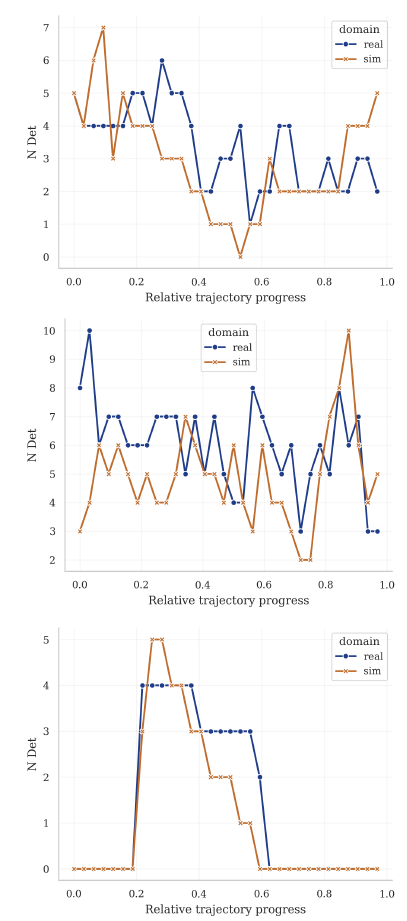
Que un entorno simulado se parezca visualmente al real es una cosa. Que los modelos de visión artificial se comporten igual en ambos es otra distinta. Puedes tener una reconstrucción que visualmente parece razonable y aun así los detectores reaccionan de forma completamente diferente. O al revés: una reconstrucción con diferencias visuales notables donde los modelos se comportan de manera sorprendentemente parecida.
Para explorar esto, ejecutamos tres modelos sobre los mismos 48 pares de fotogramas sincronizados: YOLO v2 6x-seg, RT-DETR-L y SAM3. Los tres en la misma configuración para el dominio real y el simulado. Sin filtrar clases, sin ajustes entre dominios.
Qué miramos exactamente
No teníamos ground truth para comparar predicciones contra verdad absoluta. Lo que hicimos fue comparar cómo se comporta cada modelo en el vídeo real frente a cómo se comporta en el simulado, fotograma a fotograma.
Para eso usamos varios descriptores por fotograma: cuántas detecciones produce el modelo, cuántas clases distintas predice, cuál es la confianza media, y cuánto espacio ocupan las cajas o las máscaras en la imagen. Luego calculamos la correlación de Pearson entre el valor de cada descriptor en el dominio real y en el simulado a lo largo de la trayectoria.
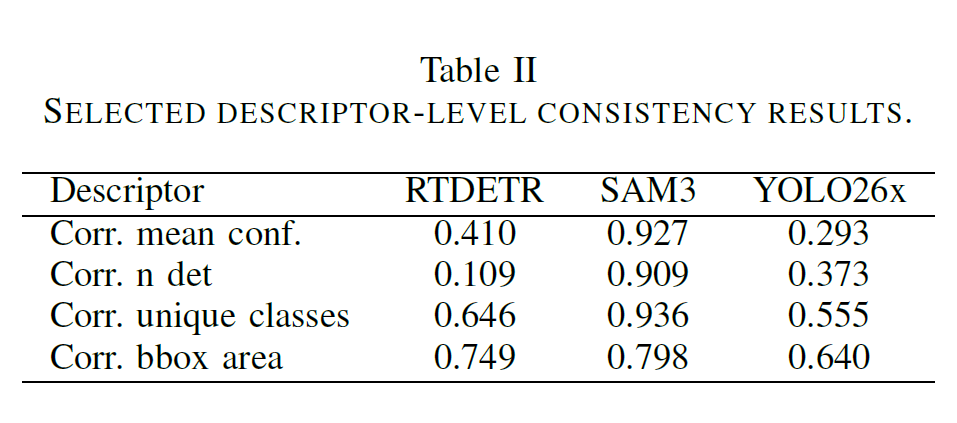
Lo que dice la tabla
Los tres modelos se comportan de forma bastante distinta.
SAM3 es el más consistente entre dominios. La correlación en número de detecciones es 0.909, en confianza media 0.927, y en clases únicas 0.936. Los descriptores globales se mantienen alineados entre lo real y lo simulado a lo largo de casi toda la trayectoria. El modelo «ve» la escena de una forma parecida en los dos entornos si miras sus estadísticas agregadas.
RT-DETR presenta un patrón diferente. Mantiene una correlación razonable en el área de las cajas (0.749), lo que significa que la cobertura espacial global se preserva. Pero la correlación en número de detecciones cae a 0.109. Puede que el espacio ocupado por los objetos detectados sea similar, pero el modelo no está detectando los mismos objetos ni la misma cantidad en los dos dominios.
YOLO queda en un punto intermedio. Correlaciones moderadas en descriptores espaciales, pero peores en confianza y conteo de detecciones. Ni tan consistente como SAM3 ni con el patrón específico de RT-DETR.
El problema del acuerdo a nivel de instancia
Los descriptores globales cuentan una historia, pero no te dicen si el modelo está detectando los mismos objetos concretos en los dos dominios. Para eso miramos el IoU de cajas y máscaras entre detecciones emparejadas, y la proporción de predicciones sin pareja.
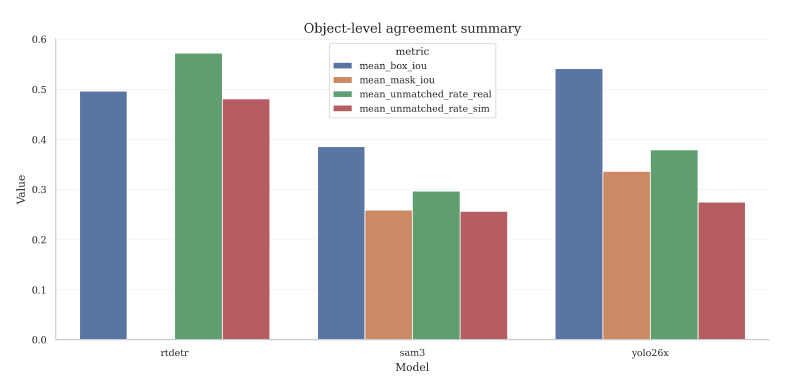
El resultado aquí invierte el orden que veíamos antes. YOLO consigue el IoU de caja más alto (0.541) y el IoU de máscara más alto (0.336) entre detecciones emparejadas. SAM3, que era el más consistente en descriptores globales, baja bastante en estas métricas. La explicación no es que SAM3 segmente mal cuando detecta. Es que hay objetos que aparecen en el vídeo real que en el simulado directamente no los detecta, así que no hay pareja posible. Puedes preservar muy bien las estadísticas agregadas y aun así fallar en objetos individuales concretos.
Consistencia temporal
Más allá de comparar fotogramas individuales, tiene sentido mirar si las predicciones son estables a lo largo del tiempo dentro de cada dominio, y si esa estabilidad es parecida en los dos.
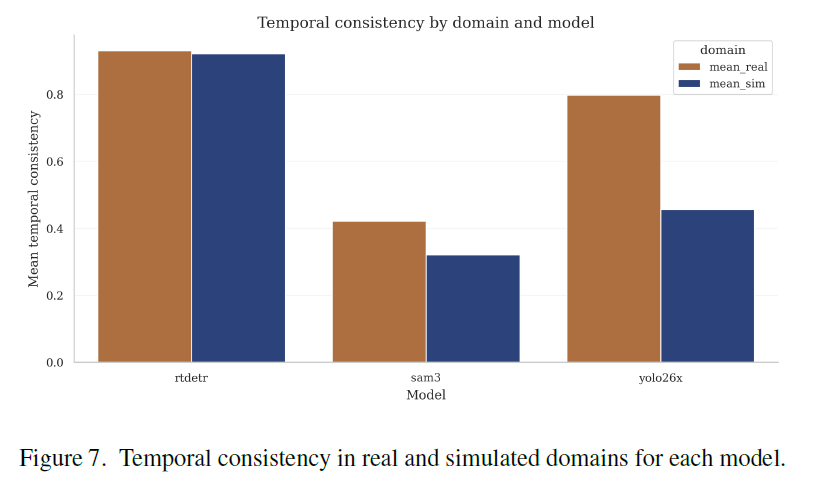
RT-DETR es el más estable. Pasa de 0.930 en el dominio real a 0.921 en el simulado. Una diferencia mínima. SAM3 baja de 0.422 a 0.321. YOLO tiene la caída más grande: de 0.798 en real a 0.456 en simulado. En el entorno simulado, sus predicciones fluctúan bastante más de un fotograma al siguiente.
La correlación temporal cruzada entre dominios sigue el mismo patrón: SAM3 llega a 0.503, RT-DETR a 0.441, y YOLO cae a 0.024. En términos prácticos, la evolución temporal de las predicciones de YOLO en el simulador no tiene casi relación con la del vídeo real.
Lo que se puede sacar de aquí
El ranking de modelos cambia dependiendo de qué aspecto mires. SAM3 gana en consistencia de descriptores globales. YOLO gana en acuerdo espacial por instancia cuando hay pareja. RT-DETR gana en estabilidad temporal entre dominios.
Eso ya dice algo importante: no hay una sola forma de medir si un modelo se comporta igual en real y en simulado. Según el criterio que uses, el mejor modelo cambia. Y el dominio simulado no afecta a todos los modelos de la misma manera ni en las mismas condiciones.